TL;DR
The Problem: AI detectors suffer from high false positive rates, making them unreliable for production use.
The Issue: AI detectors often “cheat” by learning surface-level features like topic and length instead of the subtle stylistic differences between human and AI-generated text.
Pangram’s Solution: They forced the model to learn from subtle differences by generating “synthetic mirrors” of human-written text and using a selective curriculum to focus on hard negative examples to reduce false positive rates.
Results Claimed: Over 38x lower error rates on comprehensive benchmark comprised of 10 text domains and 0% false positive rate on 98 TOEFL essays.
Why current AI detectors struggle
Almost all AI detection tools suffer from high false positive rates.
- Commercial AI detectors often have high false positive rates.
- Zero-shot detection tools have been shown to be biased against non-native English speakers, likely due to their sentence formation being simpler.
- Perplexity-based AI detection tools fail on human-written text that appears in the training dataset for the LLMs (e.g., Harry Potter).
- Deep learning-based tools are not robust to out-of-domain examples.
Why “just scale it up” doesn’t work
Pangram believes that the only way to train a production-level AI classifier is to train it on a large-scale dataset comparable in size to the datasets that are used to train modern LLMs. But if you do this naively by just throwing data and compute at the model, it doesn’t work.
Why?
Well, because it works for a large number of examples in the training set, so each step has near-zero loss. Therefore, the model isn’t able to learn further, reducing the efficiency per unit of compute drastically and making it extremely cost-ineffective. Worse, if your training data distributions for human text and AI-generated text differ significantly in topic and length, then the model will learn to cheat and classify the text based on those features instead of learning the subtle differences between AI-generated and handwritten text.
Pangram’s solution
To overcome these challenges, Pangram came up with a novel algorithm using two core techniques.
1. Synthetic Mirrors
The goal is to force the model to ignore topics, length, and other parameters and focus on the subtle stylistic differences.
The solution: for each human text example, generate an AI-generated version of the same example.
How it works:
- Input: Human example of a 200-word bad review of an Italian restaurant.
- Prompt: “Write a 1-star review for an Italian restaurant; make it 200 words long.”
- Output: A mirrored version of the original text.
2.Selective Curriculum (Hard negative mining)
Generating synthetic mirrors for each training example is too expensive and wasteful, as most examples are easy to classify anyway. So they actively choose the examples that confuse the model (false positives), create synthetic mirrors for those examples, and then retrain the model on these selected examples until loss stabilizes.
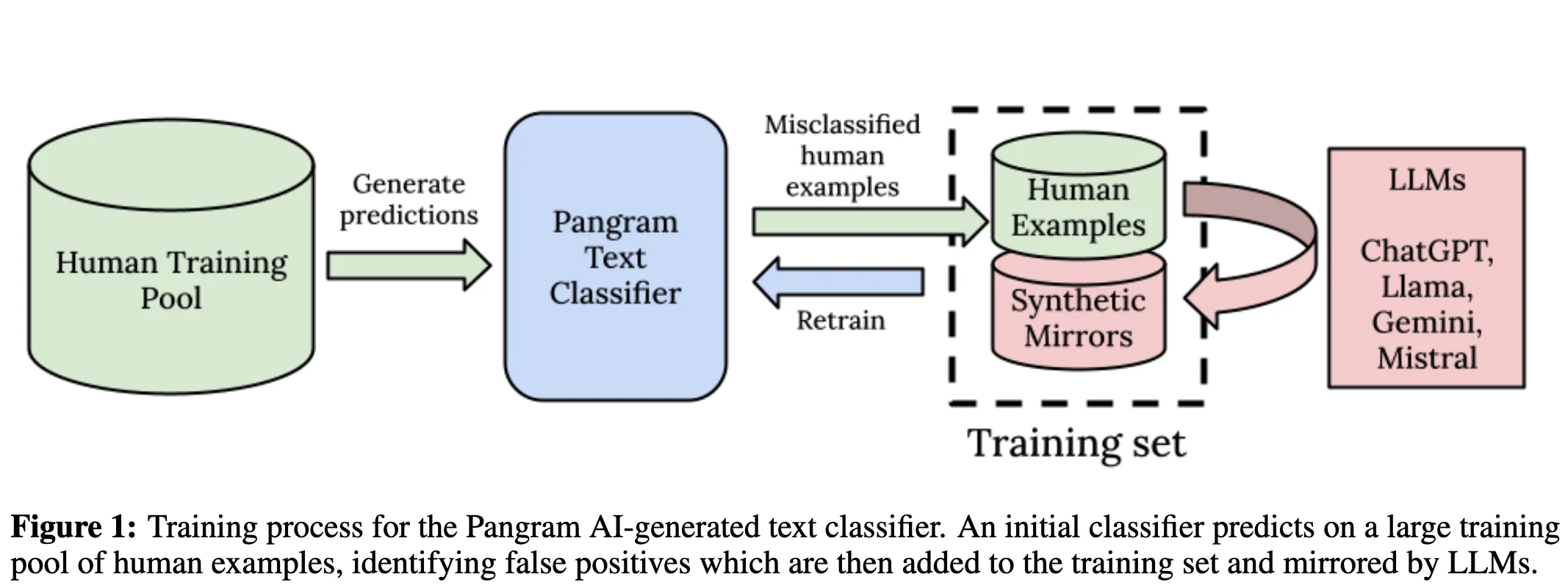
Model and algorithm
Model: Slightly modified transformer-based neural network
Algorithm:
- Sample a training set from a pool of human examples.
- For each example in the training set, generate synthetic mirrors. This helps the model learn from subtle differences rather than other obvious parameters.
- Train the classifier on this initial training set.
- Loop until loss stabilizes:
- Predict using the trained model.
- Randomly sample false positives from predictions.
- For each sample, create a synthetic mirror.
- Create a new training set which contains the old training set + false positives + mirrored false positive examples.
- Train the model using the new dataset.
Results
Across a 10-domain × 8-LLM benchmark, Pangram reports ~99% accuracy and claims lower than 38× error rates than leading commercial tools in the market. Pangram also claims 0% FPR when checked against 91 TOEFL essays, showing no bias against non-native English speakers.
Why this was interesting to me
I came across this paper after Dev’s comment that some posts sound AI generated, and it made me curious about the core question: if LLMs are already extremely good at imitating human writing, what signal is left for a detector to pick up?
This paper argues that the signal exists but it’s subtle and that the bigger challenge is preventing the model from taking shortcuts (topic, length, and other surface cues). That framing is what I found most interesting.
Overall, it was a fascinating read.
P.S. I think Pangram Labs should consider creating badges that people can display on LinkedIn/X or share in posts. Many people I know take genuine pride in writing their own content.
References
- Pangram Labs — Technical Report on the Pangram AI-Generated Text Classifier (arXiv)
- Mitchell et al. — DetectGPT: Zero-Shot Machine-Generated Text Detection using Probability Curvature (arXiv)
- Liang et al. — GPT detectors are biased against non-native English writers (arXiv)
- Hugging Face — Zero-shot classification explainer
- Hugging Face Transformers — Perplexity docs
- Wikipedia — Perplexity (info theory + NLP)